
中金研究:AI端侧落地加速,开启实时互动新纪元
本周Open AI与谷歌分别发布新一代模型:GPT-4o和Gemini系列模型。本文将介绍两大AI巨头在大模型领域的进展,并围绕硬件、操作系统、算力等方面进行探讨。我们认为,随着AI在端侧的逐渐落地,将带动消费电子终端创新升级,并对云端算力硬件系统尤其是推理侧需求提出更高要求。
摘要
Gemini 1.5 Pro与GPT-4o有何异同?我们认为,GPT-4o是端到端模型的创新,带来人机交互方式新突破;谷歌Gemini性能升级,AI能力广泛接入旗下生态。对比来看,两者都是原生多模态大模型,有望引发行业的效仿热情,原生多模态或成为未来发展趋势;但差异点在于,Gemini上下文窗口更大,且定价更具吸引力;GPT-4o模型性能更强,且更强调实际应用场景中的人机交互创新。
AI端侧落地带来消费电子终端人机交互方式变革,关注操作系统升级及应用前景。在硬件侧,我们认为,此次两大模型发布从四个方面加快了AI落地端侧的进度:1)多模态交互方式革新;2)AI语音助手拟人化;3) AI功能在移动设备的应用前景;4)商业化前景。虽然当前大模型仍以云端算力调用为主,但从当前各家在模型参数压缩的努力,结合端侧商业变现的前景,未来部分算力下沉到端侧将成为必由之路,对应消费电子终端在硬件层面也将迎来创新升级。在操作系统及应用侧,语音助手拟人化程度提升,一方面使AI agent成为可能,另一方面未来交互方式变化或带来流量入口变化,深刻影响生态格局。
云端算力硬件:GPT-4o部分功能的免费开放,Gemini能力的提升或对单位算力成本下探提出要求,AI infra面临大幅优化。我们看到,当下行业对算力硬件性能、成本的衡量以训练导向逐渐转为推理导向。除了芯片端、网络硬件端(如光模块)持续升级外,系统工程能力也正不断强化:为获得更低的硬件利用率,降低推理成本,优化显存、实施算子融合/算子实现优化、低精度(量化)推理、分布式推理均是主流实现方式。我们认为算力硬件市场有望随应用落地步入以价换量时代,市场规模或将持续增长。
风险
AI算法技术及应用落地进展不及预期,AI变现模式不确定,消费电子智能终端需求低迷。
正文
GPT-4o VS谷歌Gemini:大模型迭代到哪了?
图表1:谷歌I/O大会与OpenAI春季发布会内容一览

资料来源:谷歌2024年I/O大会,OpenAI春季发布会,中金公司研究部
Open AI:GPT-4o是端到端模型的创新,带来人机交互方式新突破
5月13日,OpenAI在春季发布会上推出新一代旗舰模型GPT-4o(o为omni,即包罗万象之意)。GPT-4o在GPT-4的基础上新增语言处理能力,可接受文本、音频和图像的任意组合作为输入,并生成文本、音频和图像的任意组合输出;同时在时延、人类语气模拟、表达等方面更加接近人类表达,是迈向更自然人机交互的一步。
模型侧:解锁更多实时应用场景
低延迟、迅速响应提升语音助手拟人化能力。在GPT-4o之前,使用语音模型对话的平均延迟时间为2.8秒(GPT-3.5)和5.4秒(GPT-4)。得益于从三个模型到一个端到端模型的转变,GPT-4o能在232毫秒内对音频输入做出反应,平均反应时间为320毫秒,这与人类在对话中的反应时间相近,提升了用户体验。
免费开放、API调用性价比提升,有望打开商业化空间。OpenAI在发布会上宣布GPT-4o将免费提供给所有用户[1],付费用户则可以享受五倍的调用额度。GPT-4o API相较于GPT-4 Turbo API,速度提升了2倍,价格仅为一半。
应用侧:语音助手打开AI实时互动场景空间
此外,GPT-4o发布会也将重点放在了AI与实际应用场景的结合上。在大会上,Open AI展示了众多GPT-4o以语音助手的方式与使用者进行多模态交互的实际场景,包括执行语音搜索、图像识别、情感反馈识别等。这些实际场景的展示,使市场看到了未来AI潜在应用落地场景的广阔空间。
图表2:GPT-4o功能特点及应用场景情况

资料来源:OpenAI官网,上海开理悟智科技有限公司官网,中金公司研究部
谷歌:Gemini性能升级,AI能力广泛接入旗下生态
2024年5月14日,谷歌召开2024年I/O大会,并发布了一系列大模型产品以及AI应用。我们看到,OpenAI和谷歌双方前后分别召开新品发布会,大有相互较量之势,例如Gemini 1.5 Pro之于GPT-4o、Project Astra之于ChatGPT-4o、Gems之于GPTs、Veo之于Sora等,体现出谷歌正加速缩小与OpenAI在AI大模型方面之间的差距。此外,我们认为AI Overview、Ask Photos、AI Workspace等功能的推出,也反映出谷歌正积极凭借自身的产业、生态优势,推动AI与应用的融合。
模型侧:深化大模型在端侧的部署
Project Astra对标ChatGPT-4o,打造更流畅、更丰富的人机交互体验。Project Astra基于谷歌Gemini大模型,能够同时处理视觉、语音等多模态信号,并展现出较强的理解、记忆和即时响应能力。我们观察到,演示中Project Astra至少在智能手机(Google Pixel)以及智能眼镜(prototype glasses)两个硬件设备上运行,我们认为AI大模型正加速向各类智能终端侧部署应用。
图表3:Project Astra演示demo

注:左图为智能手机端运行,右图为智能眼镜端运行;资料来源:谷歌2024年I/O大会,中金公司研究部
端侧应用功能迎来升级。1)Gemini Nano:目前运行于端侧的Nano模型仅用于文本模态,谷歌宣布将于今夏实现实时语音交互功能[2],并在今年晚些时候上线视频交互功能,多模态功能趋于完善。2)Gems:与OpenAI的GPTs类似,Gems能够定制具备特定特征的AI助理,为使用者提供健身、陪伴、烹饪、编程、写作等任务的个性化协助。3)安卓系统升级:谷歌宣布新增三项AI功能:Circle to search、AI agent、模型本地化部署,在保障隐私安全的情况下,提升安卓系统的智能化水平。
应用侧:搜索、相册、音视频、办公,谷歌生态广泛AI化
谷歌凭借本身在生态上的优势,积极推动AI与应用的融合。1)搜索:AI Overview能够在搜索中自动总结全网内容,实现概览、推理、规划、排版等功能。2)相册:Ask Photos通过自然语言实现对特定相册照片的搜索。3)办公:在AI Workspace中新增工作总结、邮件问答、智能回复等功能,将AIGC赋能企业自动化,提升办公生产效率。4)多模态:谷歌推出Imagen 3、Music AI Sandbox、Veo等大模型,分别对应图像、音乐、视频生成;其中Veo模型能够根据多种模态信息的提示,生成时长超1分钟的1080P高清视频,与OpenAI Sora的差距进一步缩小。谷歌当前产业覆盖智能终端、互联网、企业、医疗、无人驾驶等多个产业,作为一家生态布局相当广泛的科技大厂,我们认为谷歌在应用侧落地具有先天的优势。随着大模型技术的不断成熟,我们预计谷歌有望加速应用落地。
对比:Gemini 1.5 Pro与GPT-4o有何异同?
相同点:两者都是原生多模态大模型,指引技术发展趋势
传统的多模态大模型,往往是不同模态的模型分别训练后再融合在一起,虽然能够用一个大模型实现对不同模态数据的处理,但是不同模态之间缺乏协调性。而Gemini和GPT-4o的训练语料同时包括文本、图像、音视频等多种模态数据,所有输入输出都是在同一个神经网络中进行处理。从两家的demo来看,最终的效果是大模型能够同时理解多模态信息以及信息之间的关系。我们认为,谷歌和OpenAI两大行业领先企业均不约而同开发原生多模态大模型,有望引发行业的效仿热情,原生多模态或成为未来发展趋势。
图表4:传统多模态大模型架构
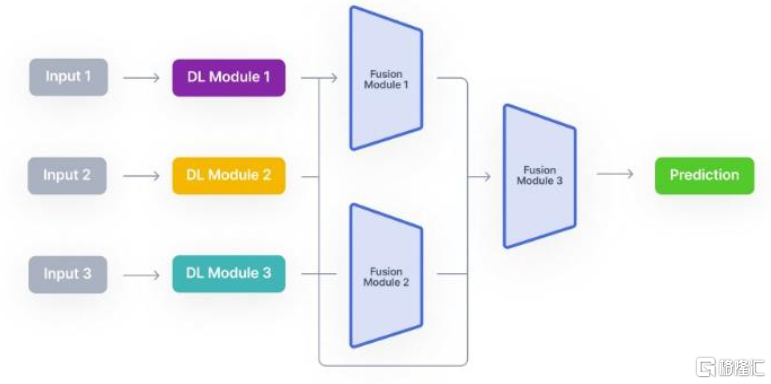
资料来源:V7 Labs,中金公司研究部
图表5:Gemini原生多模态大模型
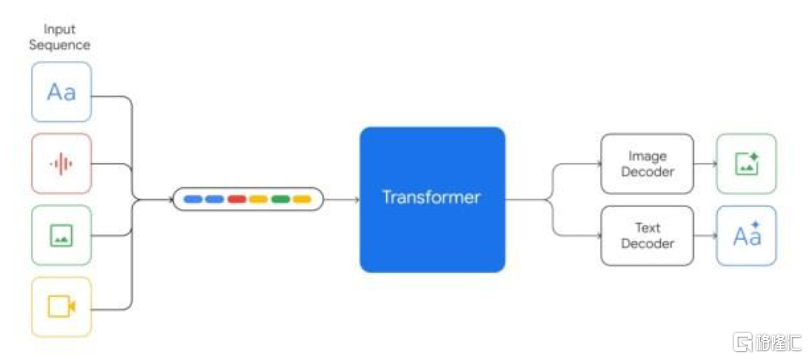
资料来源:谷歌官网,中金公司研究部
差异点:Gemini上下文窗口更大,GPT-4o展现了更多的应用场景
Gemini上下文窗口更大。2024年I/O大会上,谷歌宣布将Gemini 1.5 Pro的上下文窗口token数由100万个扩容至200万个,相当于2小时视频、22小时音频、超过6万行代码或超过140万词文本的数据体量,遥遥领先于其他大模型(Claude 3为20万个tokens,而GPT-4o仅为12.8万个)。
图表6:Gemini 1.5 Pro、Claude 3、GPT-4 Turbo上下文窗口长度对比
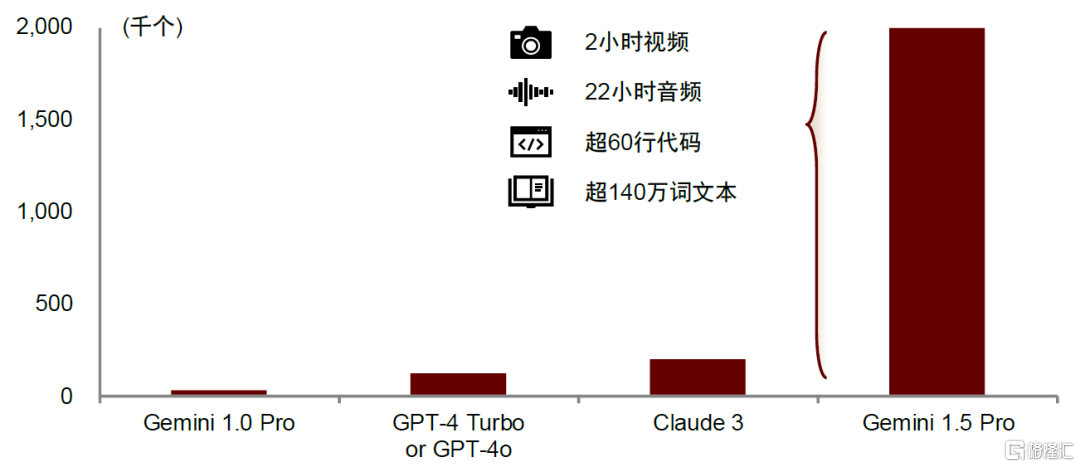
资料来源:谷歌官网,中金公司研究部
Gemini定价更具吸引力。我们以12.8万个tokens上下文长度为例,根据谷歌官网信息,Gemini 1.5 Pro输入、输出价格分别为3.5美元/1M tokens、10.5美元/1M tokens,对比GPT-4o(上下文窗口为12.8万个tokens)输入5美元/1M tokens、输出15美元/1M tokens的定价,Gemini 1.5 Pro的调用成本较GPT-4o下降30%。
图表7:Gemini 1.5 Pro与GPT-4o的定价
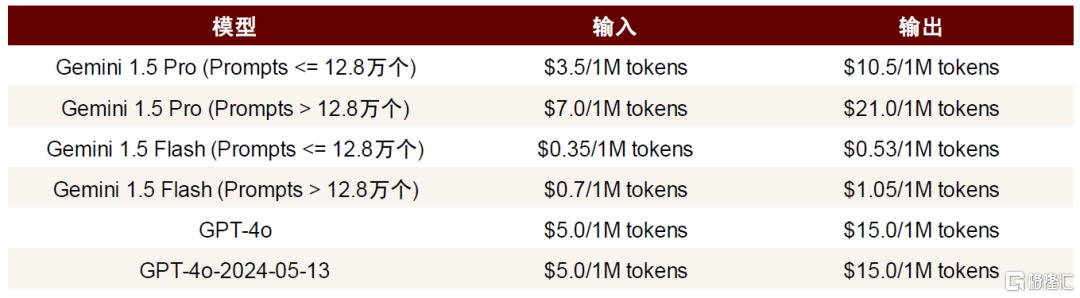
注:GPT-4o上下文tokens长度为12.8万个; 资料来源:谷歌官网,OpenAI官网,中金公司研究部
GPT-4o更强调实际应用场景中的人机交互的创新。我们能看到,GPT-4o发布会并未过多展示技术细节,而是将大量时间用于展示GPT-4o如何在手机/PC产品上可能的应用场景,尤其AI语音助手充当了重要角色,在跨模态的人机交互中表现出色。
GPT-4o模型性能更胜一筹。根据OpenAI官网测评数据,GPT-4o在文本测试(如MMLU、MATH、HumanEval等)以及视觉理解测试(如MMMU、MathVista等)各类任务中均取得较Gemini 1.5 Pro更优的表现。我们认为,OpenAI的技术水平仍然领先于行业。
图表8:主流大模型文本、视觉理解测试性能对比
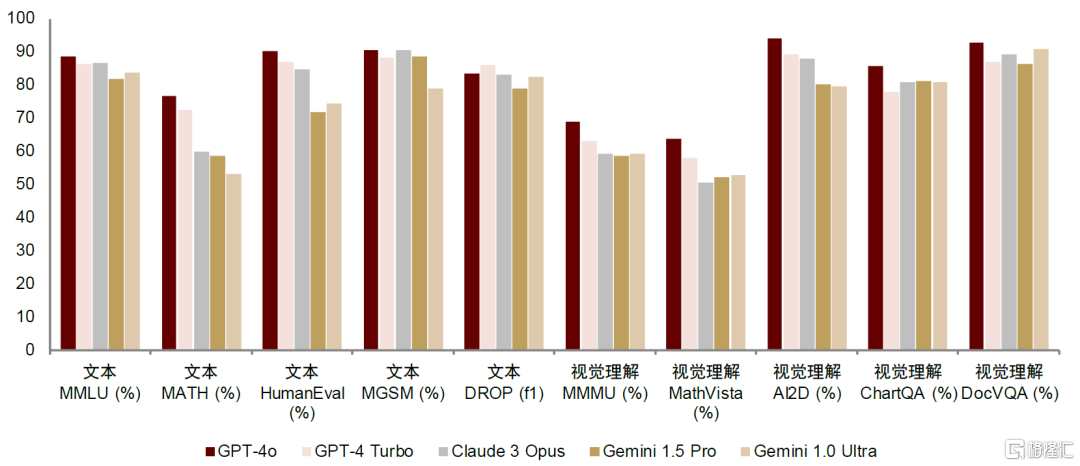
资料来源:OpenAI官网,中金公司研究部
终端硬件:人机交互方式变革,AI端侧落地加速
在AI发展逐渐进入应用变现的下半场后,如何将AI能力赋能给To C端的消费者成为了重要课题。我们观察到,除了常规的模型及技术发布外,本次GPT-4o及谷歌发布会均将部分重点放在了展示AI在移动设备,如手机、PC等的实际应用场景。我们认为,未来AI在端侧的应用和消费者触达变现或将成为新的发展侧重点。
AI 消费电子终端,硬件升级趋势明确
AI 手机/PC:多模态能力改变人机交互模式
AI手机/PC渐行渐近,AI端侧落地前景拓宽。
► 交互方式革新:端到端的多模态能力,使得人机交互方式不再局限于文本,丰富了交互形态,与手机现有应用的协同作用更强。
► AI语音助手拟人化:低时延、能够随时打断、根据即时反馈灵活调整输出,和丰富的情感色彩,使AI语音助手更加拟人化,改变了过去AI语音助手只能以回合制方式机械回答的冰冷形象。
► AI功能在移动设备的演示,应用场景拓展:谷歌Gemini模型与安卓生态的结合、GPT-4o在iPhone上的演示,让消费者看到了在手机系统与AI结合的可能,AI调用现有APP甚至跨APP的打通成为可能,并拓展出更为丰富的应用场景。
► 商业化前景:除了多元的应用场景外,GPT-4o面向免费用户开放,考虑手机/PC这类To C市场的庞大用户群体,AI在端侧的广阔前景受到更多关注。
图表9:GPT-4o可以改变不同语调回答用户问题

资料来源:GPT-4o发布会,新智元,中金公司研究部
图表10:GPT-4o在平板上指导用户做数学题

资料来源:GPT-4o发布会,中金公司研究部
AI手机:当前小米、三星、谷歌等厂商均陆续推出了自己的AI手机产品。Counterpoint预测,2024年全球AI手机渗透率约8%,出货量有望超1亿部;2027年全球AI手机渗透率约40%,出货量有望达5.22亿部。
图表11:各品牌最新发布的AI手机

注:统计时间截至2024年5月15日,为不完全统计 资料来源:各公司官网,中金公司研究部
AIPC:AIPC上市或推动PC换机周期到来。考虑到AI在提高生产力、促进应用落地创新的潜在能力,IDC预测,AIPC 有望在2027年渗透率达到85%。
图表12:各PC厂商对AIPC产品的布局情况

资料来源:联想官网,惠普官网,戴尔官网,宏碁官网,荣耀官网,中金公司研究部
AI 可穿戴:关注AR空间计算与AI的结合
GPT-4o应用展现空间计算雏形,兼具空间感知及用户感知。从空间感知层面,GPT-4o展示了初步的识别能力,用户可以通过摄像头识别手写方程,提供解题提示,并逐步引导解题过程,实时提供反馈;同时从用户感知层面,GPT-4o可以感知用户的面部、姿态、语音和表情、情绪变化,其理解人类对话中的打断习惯,能够适时停下来听,并给予相应回复,根据用户语调生成自然、连贯且毫无机械感的对话。我们认为GPT-4o应用展现了空间计算的雏形,虽然在三维重构、空间感知、用户感知等领域仍存在一定的提升空间,但新的软硬结合生态及交互模式正在被逐步构建。
图表13:GPT-4o在“视频通话”中感知用户面部表情
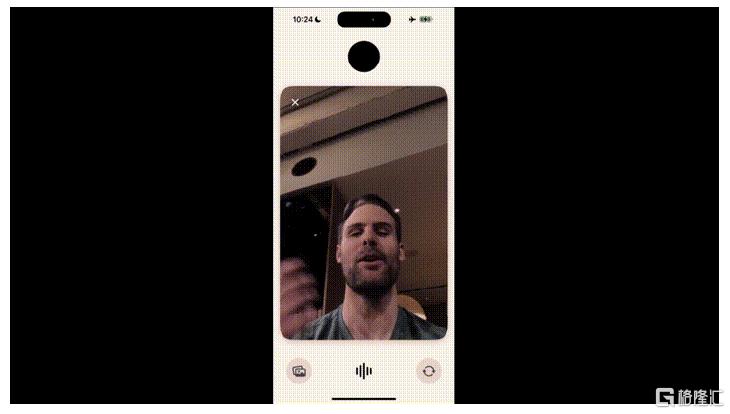
资料来源:OpenAI GPT-4o发布会,中金公司研究部
AI落地端侧的优势在于对周边感知数据的利用,与空间计算相辅相成,或将引领AR产品走向更多应用场景。我们看到,目前Meta推出的Meta RayBan等AR眼镜产品已经陆续出现了基于多模态的AI用例。硬件端,芯片厂商同步发力,对AR的重视程度不断提高,产品定义从手机配件变为独立设备。
硬件升级趋势:关注硬件侧变化
我们认为未来部分算力下沉到端侧将成为必由之路。
图表14:AI手机硬件升级趋势

资料来源:《AI手机白皮书》(IDC及OPPO,2024年),IDC官网,中金公司研究部
图表15:AIPC硬件升级趋势

资料来源:Counterpoint,Trendforce,中金公司研究部
操作系统&应用:AI进入实时互动新纪元,关注操作系统升级及应用前景
人机互动升级,实时交互能力拓展AI应用落地场景
多模态交互能力较大丰富了AI应用的可能场景。此次GPT-4o端到端的交互能力,使得语音、文本、视频、图像等不同模态的打通成为可能,较大丰富了使用的场景。
图表16:手机App Be My Eyes接入GPT-4o辅助盲人通过摄像头进行周围环境搜索并输出语音

资料来源:OpenAI GPT-4o发布会,中金公司研究部
图表17:谷歌Gemini “Ask with Video”可实现视频搜索功能

资料来源:谷歌2024 I/O大会,中金公司研究部
关注苹果与安卓两大阵营,底层系统打通将成趋势
安卓生态:谷歌Gemini放大全生态优势,有望打通安卓底层系统。更进一步地,我们认为未来AI与消费者的交互离不开大模型与手机操作系统的深度结合,包括底层操作系统的权限开放、跨APP的内容调用及统一输出等。在这方面,谷歌基于其在安卓生态的强大影响力,已经开始布局。在本次I/O大会上,谷歌展示了Gemini与谷歌原生产品,尤其是安卓操作系统层面的深度结合。谷歌表示,本地运行的多模态Gemini Nano模型将登陆Pixel手机,Gemini APP将支持语音及视频实时交互;谷歌将推出自定义AI助手功能Gems,可与“谷歌全家桶”进行交互。展望未来,我们预计谷歌有望凭借自身在安卓生态的强大优势,加速其在移动设备,尤其是安卓手机领域的AI功能渗透。
图表18:谷歌2024年I/O大会对安卓系统的升级
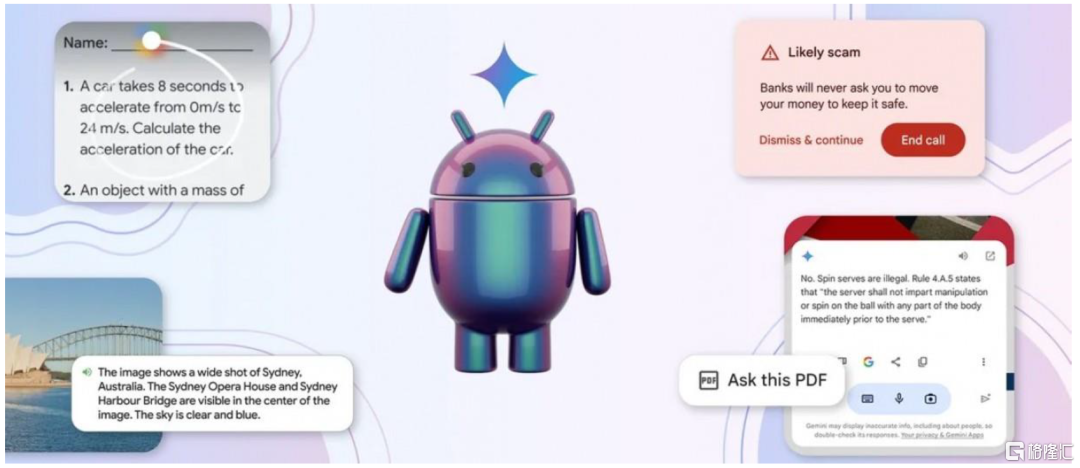
资料来源:谷歌2024年I/O大会,中金公司研究部
苹果:端云协同,优化用户体验,推动终端加速智能化发展。本次GPT-4o展示主要以iPhone为主,同时也有Mac的亮相。除了手机APP端,OpenAI还推出了适用于macOS的桌面级应用。此前有新闻报道[3],苹果正在与Open AI及谷歌就AI方面合作进行谈判。我们认为苹果在生成式AI或将通过端云混合的方式实现,在手机、平板、电脑及MR等端侧,苹果可以通过A M系列芯片算力支持,完成中小模型训练,需要时也可向云端借用算力以完成训练要求。当前苹果已积累大量原生App,如Music、TV 、Fitness 及News等,我们认为苹果在云端大模型(如Ajax等)训练后,结合用户日常搜索及使用习惯,有望实现个性化用户推送。考虑苹果已收购的AI Music等初创公司,我们认为苹果有望结合用户偏好实现定制化内容生成,进一步提高用户粘性。
图表19:苹果AI模式探索(*号表示苹果暂未正式发布,但未来有布局潜力方向)
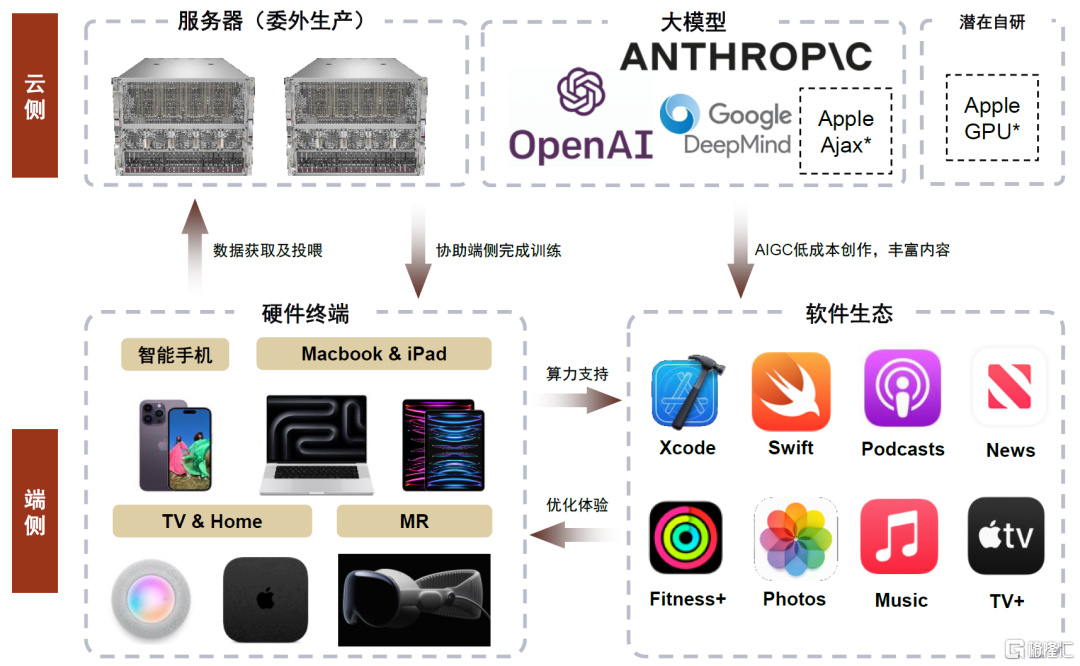
资料来源:苹果官网, OpenAI、Google、Anthropic官网,中金公司研究部
安卓手机厂商:除了大模型厂商外,安卓手机厂商也在加快自身大模型研发。力图在未来的AI端侧时代占得先机,目前华为、小米、OPPO、vivo、三星、传音等厂商均推出了大模型,并结合进自身的操作系统。
语音助手使AI Agent成为可能,流量入口或将迎来变化
语音助手拟人化程度提升,AI agent成为可能。此次GPT-4o最令观众眼前一亮的在于具有情感色彩、即时进行多模态反馈的AI语音助手能力,同时谷歌发布的Astra亦具有多模态的反馈能力。从移动端AI的发展趋势看,我们认为未来手机端AI Agent的发展方向是Agent自主调用手机端应用,让用户享受到专属手机智能助理的服务,从而打破APP的隔阂,通过自主的规划决策实现跨应用的操作。
图表20:GPT-4o通过语音助手方式与使用者交互
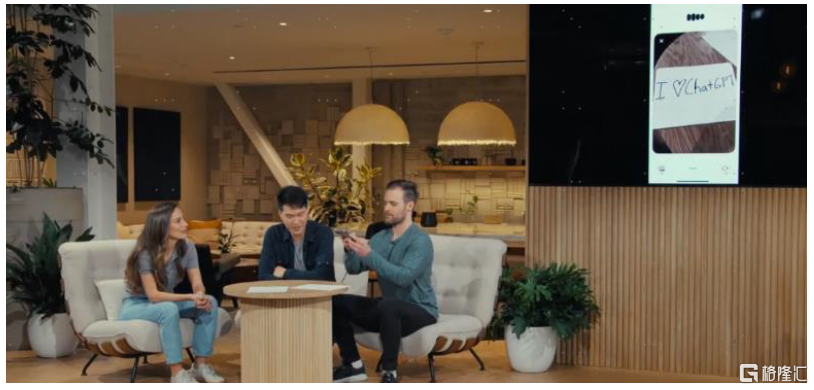
资料来源:OpenAI GPT-4o发布会,中金公司研究部
交互方式变化或带来流量入口变化,深刻影响移动互联网生态格局。我们前述AI Agent的交互模式,对应了或将替代独立APP与消费者的直接接触,而是将所有需求集成进入AI Agent中,这种人机交互方式的改变具有深远意义。我们认为未来人机交互的模式有望从文本进化到语音等方式,同时人机交互也将呈现多模态结合的特点。同时,语音助手有望成为用户获取信息及进行交互的重要入口,甚至直接帮助用户进行内容筛选和内容生成。从远期角度看,当交互出现跨APP调用后,APP以及应用商店的入口功能被削弱,当前移动互联网生态的商业模式或许将出现变化。
云端算力硬件:利用率为上,推理侧落地需求推动AI Infra进入大幅优化期
GPT-4o部分功能的免费开放,Gemini能力的提升或对单位算力成本下探提出要求,AI infra面临大幅优化。我们看到,虽然GPT-4o依旧是GPT-4级别的模型能力,但此次发布大幅度针对端侧应用进行了扩充;同时在免费有限次的使用中,交互时延缩短至232 毫秒内,逼近人类反馈。Gemini 1.5 Flash是新推出的模型,重点优化了响应时间,兼顾快速和成本效益。从功能角度看,我们认为应用能力的推广以及交互时延的降低均对于云端算力芯片的推理能力提出了更高的要求。
图表21:GPT-4o向用户开放免费使用部分功能

资料来源:OpenAI GPT4o发布会,中金公司研究部
应用加速开发推动算力资源向推理任务倾斜;推理过程预填充阶段(Prefill)对单卡算力有较高需求,解码阶段(Decode)内存带宽是推理性能限制因素。若使算力硬件系统针对推理任务优化,一方面可以直接通过升级硬件性能来解决。另一方面,由于每分每秒的GPU运行均是成本开销,所以对于实际推理任务中,我们要先去衡量究竟是何种原因导致系统效率瓶颈,并结合具体系统服务能力敏感指标来具体针对性的实施工程优化。实际应用情况中,我们多采用“以计算换存储”或“以存储换计算”来提升硬件利用率(算力利用率MFU及访存利用率MBU),以减小延时,增加吞吐量,提升硬件利用率来降低推理成本。
图表22:大模型推理优化方式详解
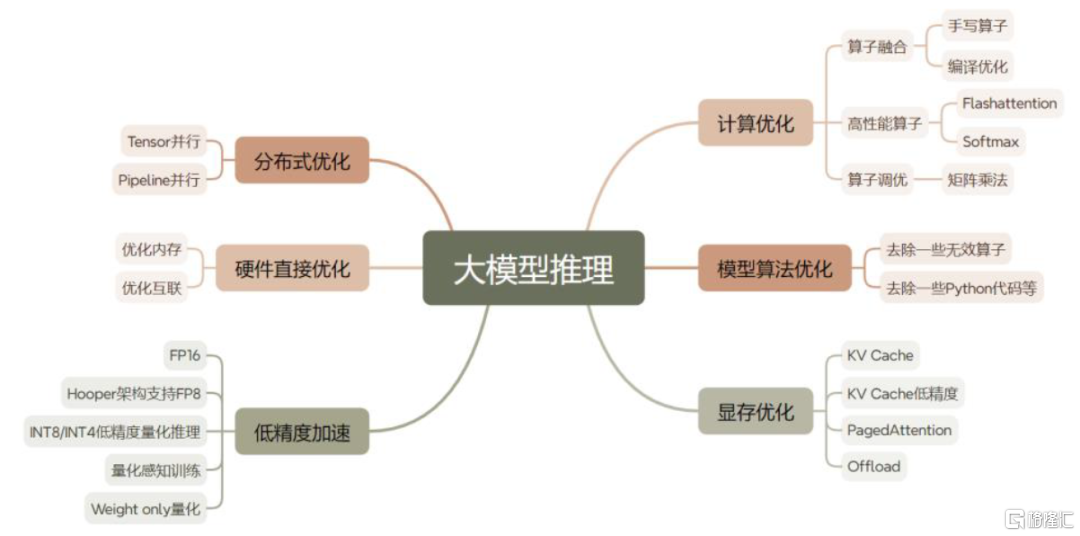
资料来源:英伟达官网,中金公司研究部
从模型创新到加速应用落地,资本开支结构或将向边缘推理侧倾斜。2023年北美头部四家云厂商(亚马逊、微软、谷歌、Meta)资本开支合计达到1474.5亿美元,结合各家指引,当前彭博一致预期认为2024年资本开支总值同比增长33%至1966.1亿美元,AIGC的发展驱动资本开支总量抬升。而结合此次GPT-4o发布会中,我们看到随着应用加速部署,AI的发展脉络逐渐从模型创新、向大模型端侧部署倾斜,由此带来的算力资源变化,或将带动资本开支结构向边缘推理侧倾斜。
硬件方面的优化
计算芯片推陈出新
英伟达推出GB200 NVL72,相比H100可为万亿参数语言模型提供30倍的实时LLM推理性能,有望助力产业探索应用开发。展望未来,我们看好GB200 NVL72凭借集成式的高算力、优异的互联能力以及大幅度的内存带宽,在推理任务侧持续助力产业界探索应用开发,提供性价比较高的算力解决方案。
图表23:GB200 NVL72与H100推理速度对比
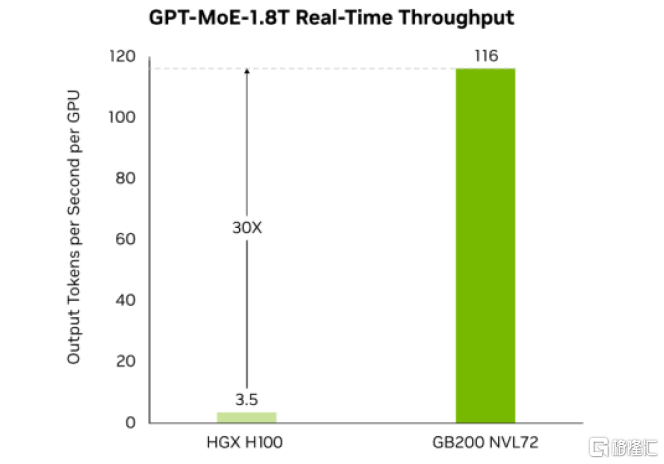
资料来源:英伟达官网,中金公司研究部
谷歌TPU迭代升级,芯片自研进一步深化。TPU v6 Trillium正式推出,谷歌表示其单片峰值计算性能较TPU v5e提高470%,能效较TPU v5e高出67%以上。从内部设计看,TPU v6扩展了矩阵乘法单元MXU,提高了时钟速度,将HBM的容量和带宽提高了一倍、片间互联的带宽亦增加了一倍,同时配备了SparseCore专用加速器优化工作负载,最终实现性能与能效的大幅提升。
图表24:谷歌TPU v6 Trillium

资料来源:谷歌2024年I/O大会,中金公司研究部
网络硬件持续迭代
我们认为,由于AI数据中心GPU并行计算需要高频中间计算结果通信,且通信效率影响整体计算集群性能,所以对通信带宽、网络时延、网络稳定性、自动化部署等提出较高需求。
C2C方面,GB200 NVL72利用全互联的第五代NVLink网络,单个GB200 Tensor核心GPU最高可支持18个100GB/s的NVLink连接,总双向带宽达到1.8TB/s,相比第四代NVLink实现翻倍,相较于2014年初代的160GB/s实现了12倍提升。
图表25:NVLink双向带宽升级至1.8TB/s
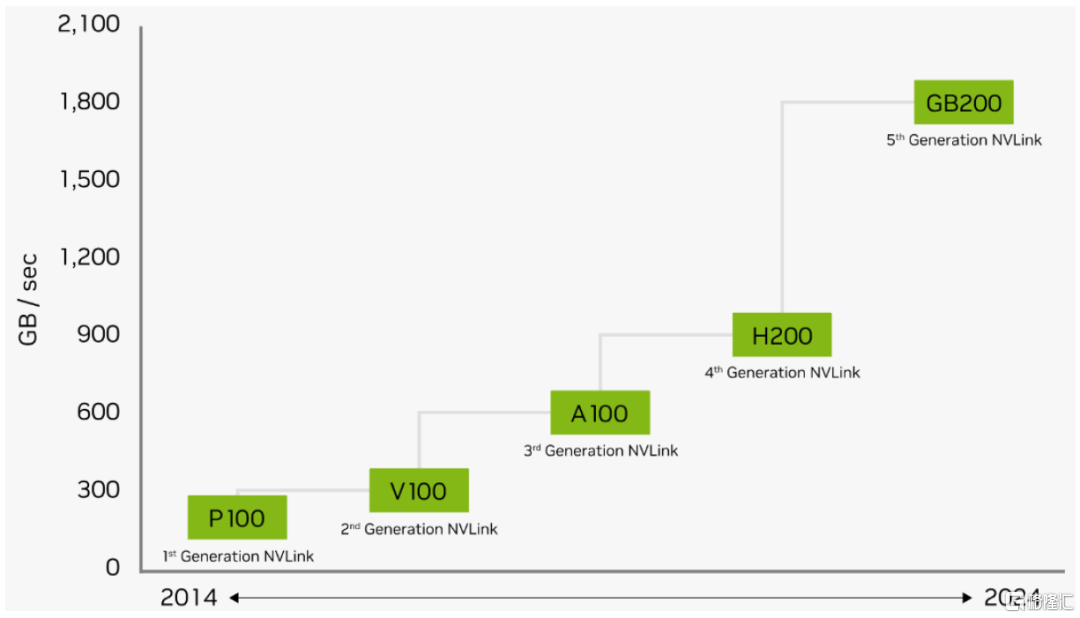
资料来源:英伟达官网,中金公司研究部
NVSwitch是NVLink技术的延伸,解决GPU间通讯不均衡问题。新一代NVLink Switch系统最多可连576块GPU,连接总带宽最高达1PB/s。
B2B方面,200G SerDes赋能,X800系列交换机带宽、端口速率同步升级。英伟达X800系列交换机和ConnectX-8网卡代表数据中心内B2B互联的最高水平。ConnectX-800G智能网卡速率升级至800GB/s,最高支持48通道PCIe 6连接;其兼具通信优化和计算卸载功能,能够与交换机协同提升B2B传输效率。
谷歌液冷数据中心稳步推进。2018年谷歌发布TPU3.0 Pod将液冷技术引入数据中心,至今部署液冷系统的数据中心已达1GW。我们认为液冷作为散热效率更高的方式,凭借提升算力部署密度及降低系统功耗的优势,有望实现对传统风冷的替代,未来渗透率有望继续提升。
系统工程的优化
1)优化显存:在推理过程中,除了模型在各个层级的权重本身占用显存外,KV Cache(即Attention块中的Key和Value矩阵,推理decode阶段减少重复计算所需要缓存的部分)也占用了较大的显存。目前大部分针对KV Cache的优化工作,主要集中在工程上。不过近期我们看到针对Attention块的创新变化也在发生,如DeepSeek在其最新发布的V2版本大模型中引入了MLA机制,获得了较好的KV Cache降低效果,模型性能也保持了不错的稳定性。我们看到业界在不断寻求更优化的方法来降低KV Cache访存开销,以此来获得更大的batch size以获得更高的硬件利用率。
2)算子融合/算子实现优化:在模型训练时,工程师一般会选择小算子反复探求每步骤输入输出结果的关系来对模型做优化,而对于推理任务来看,在模型训练完成后更多会使用大算子来获得更加的硬件执行效率。在算子实现上(即如何将计算逻辑和芯片架构相结合)也可以发掘相对较频繁执行的算子,并将其在GPU的物理实现上通过更优化的编译策略来增大单位时间内GPU利用率。
3)低精度(量化)加速:推理过程中,权重的量化是加速推理重要方法之一。在推理时,我们发现FP16 权重通常能提供与 FP32 相似的精度,这代表着在推理时通过将权重量化为FP16,仅需一半 GPU 显存就能获得相同的结果,甚至采用更低精度如INT8/INT4来量化来获得更好的效果。我们认为在一些专用处理器中往往存在一些专门为整型运算设计的加速单元,可以实现更好的算力利用率及能耗比。
4)分布式推理:虽然与训练端相比,推理的计算量相差甚远,但我们在前文中提及,大模型推理中部分场景是访存受限的(尤其对于模型升级后更长的上下文窗口这类需求)。因此为提升GPU利用率,工程上会采用张量并行(Tensor Parallelism, TP,为模型并行的一种,属于层内并行),将LLM模型参数进行切分,从而减少从显存中读取模型参数的耗时。
风险提示
AI算法落地进度不及预期:ChatGPT\GPT-4等模型不开源,同时存在着隐私数据泄露、模型窃取、数据重构、Prompt Injection攻击等数据安全性问题、回答准确性问题、道德问题,威胁着模型应用的落地。
AI变现模式不确定:虽然AI的出现或将改变数字内容生产关系,但是:1)ToC端,除了GPT-4,其他AI模型的用户还处于免费体验的模式,同时以Microsoft 365、New bing等为代表的应用也仍处于免费体验的模式,收费模式尚不确定;2)ToB端,目前大量初创企业接入的ChatGPT、GPT-4 API接口收费较低,未来的收费标准和模式也不确定。
消费电子智能终端需求低迷:受整体宏观经济、国际地缘政治冲突及半导体周期下行等因素叠加影响,消费电子市场受到较大冲击,国内外市场需求均呈现不同程度的疲软。若2024年消费电子需求回暖不及预期,我们认为硬件端受益AI的进展或将不及预期。
注:本文摘自中金公司2024年5月16日已经发布的《AI浪潮之巅系列:AI端侧落地加速,开启实时互动新纪元》;彭虎、温晗静、成乔升、李诗雯、黄天擎、孔杨、查玉洁、李澄宁、石晓彬、贾顺鹤、陈昊
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。

